本文共 4131 字,大约阅读时间需要 13 分钟。
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
本期AI TIME PhD专场,我们有幸邀请到了来自亚利桑那州立大学的博士生郭若城,为我们带来他的精彩分享——利用网络信息减少因果推断中的confounding bias—结合两种思路的新方法IGNITE: A Minimax Game Toward Learning Individual Treatment Effects from Networked Observational Data。

郭若城:亚利桑那州立大学博士生,研究方向为因果推断,数据挖掘,社交网络。2017年至今师从Prof. Huan Liu。博士期间在KDD,WSDM,IJCAI,CIKM,SDM等会议发表论文20余篇,在ACM Computing Surveys发表关于因果推断与机器学习结合的综述 A Survey of Learning Causality with Data: Problems and Methods。曾作为实习生在Google X和Microsoft Research进行因果机器学习方向的研究。

一、Intro
1、什么是因果causality?
基于随机变量的定义来说,假如我们有两个随机变量T和Y,当且仅当不通过intervention改变其他变量值的时候对T的值进行改变一定会引起Y值改变,我们说T是Y的因,Y是T的果。
2、为什么关心因果效应causal effects?
因为因果效应对于决策至关重要,是决策的依据。比如,IT公司的A / B tests,药物的临床试验。
3、为什么我们要在有网络结构的观测型数据networked observational data上研究这个问题呢?
因为在真实世界中,网络结构数据非常常见,比如:社交网络、银行体系中的支行网络。这些数据非常有用,所以我们需要研究和用好这些数据。
网络结构的观测型数据networked observational data,由n个instance和连接它们的网络结构(常用邻接矩阵表示)组成,如图所示:

图1 Networked observational data
二、Challenge and Motivation
如果不能控制隐藏的混淆变量Hidden confounders,就会产生有偏差的估测,得出的错误的因果效应。于是,我们借鉴了已有的两种从数据中学习隐变量来替代隐藏的混淆变量的方法,即Balancing the representation of confounders[1],和Predicting the treatment assignments [2],以对因果效应有更准确的估测。
三、Identification
因果效应估计的第一步是Identification,也就是需要把因果量变成统计量。其中我们用到了measurement bias[3]的思路。
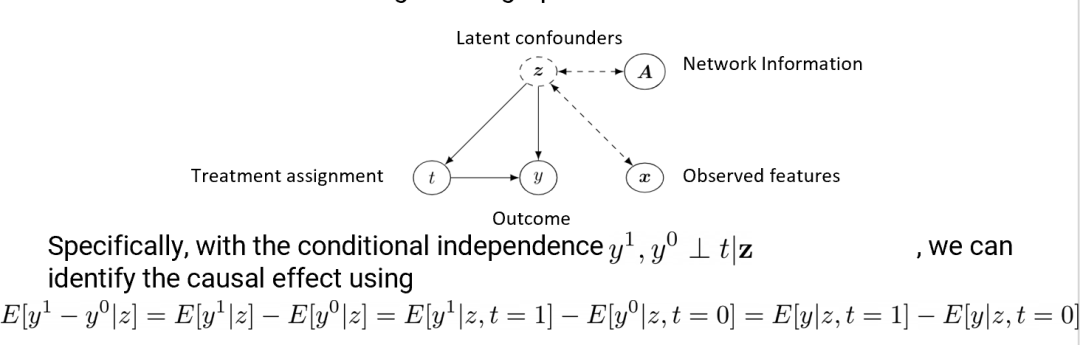
图2 Identification
四、IGNITE
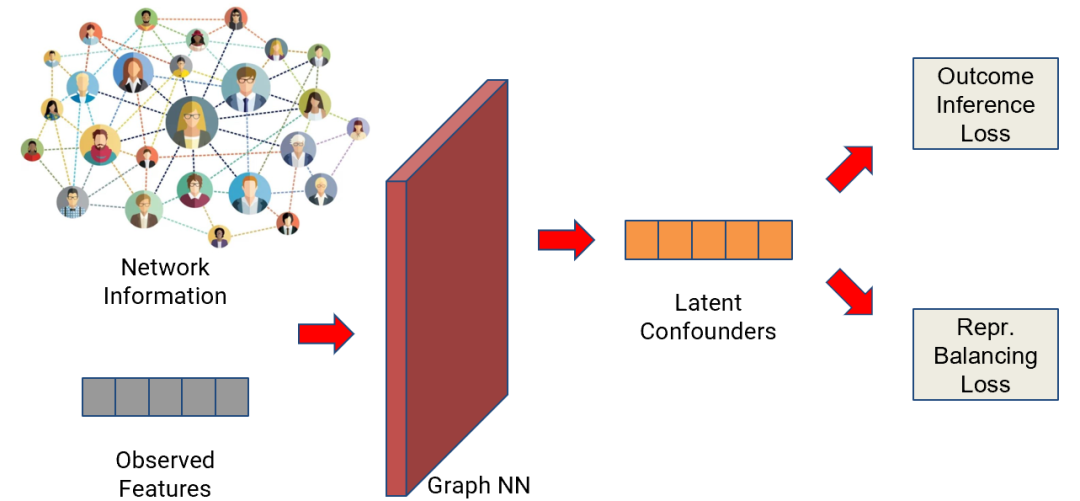
图3 IGNITE overview
我们提出了一种新的Critic based representation balancing方法,同时使用了Gradient penalty [4]的方法让训练更加稳定。
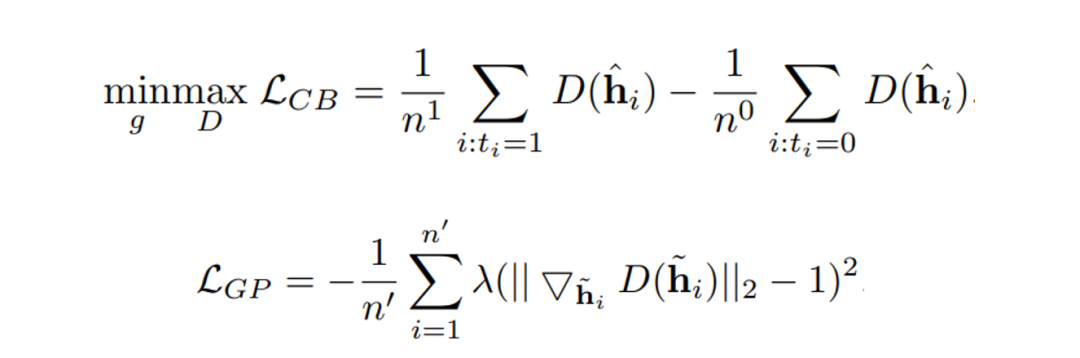
图4 Critic based representation balancing
Min step
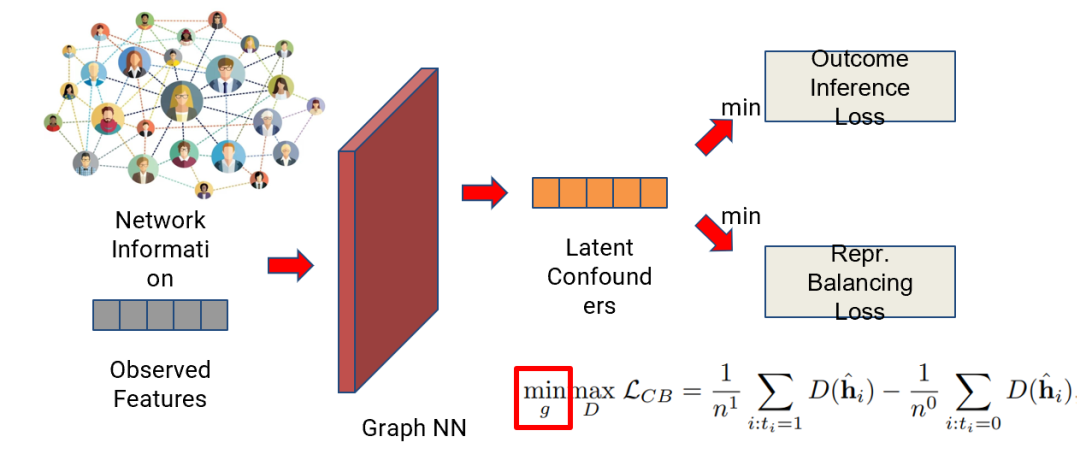
图5 Min step
我们在min step这一步会训练Graph NN和用于outcome inference的网络以做到representation balancing,同时minimize Outcome Inference Loss。
Max step
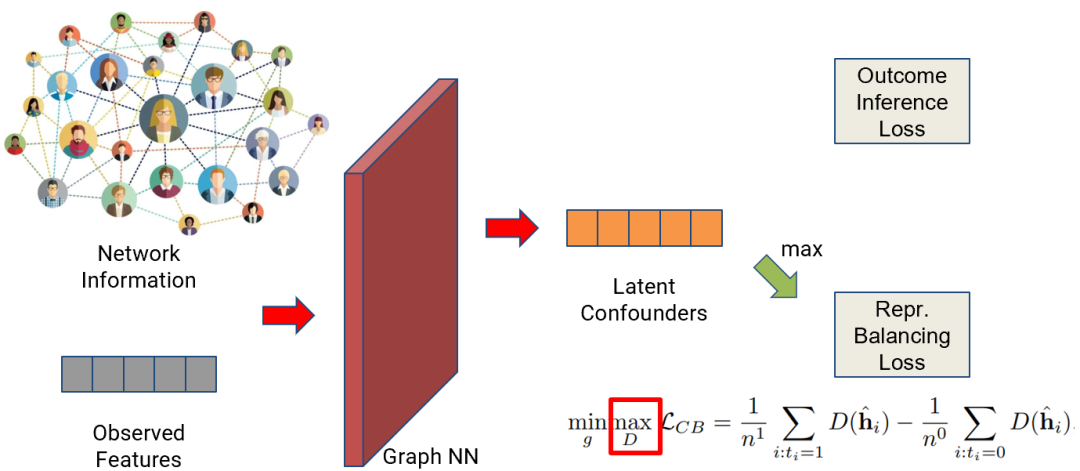
图6 Max step
在max step这一步我们不再训练和Outcome Inference相关的网络,同时固定Graph NN参数,只需训练critic,让它更加能够区别treatment group和control group对应的latent confounders分布,从而更好地丈量两个分布间的divergence。
五、Experiment
因为因果推断的特性,我们只能使用Semi-synthetic datasets。首先,我们从真实世界数据集中获取features和network information,然后基于此用公式模拟treatments and outcomes[5],我们也需要考虑多种不同hidden confounding的强度并使用K2这个参数控制,confounding越强说明问题越难,estimation bias越大。跟之前工作[6]不同的是,我们随机分配了网络边界的权重去更好地反映真实世界网络。
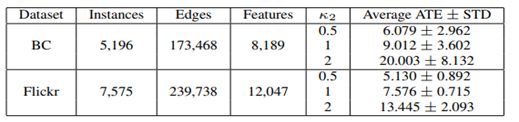
图7 Statistics of the Datasets
(Training/validation/test = 60% : 20% : 20%)
Baselines中,我们选用了SOTA neural network based和ensemble based causal inference methods,包括Ablation models: GATD+, GATD,GATDT,还有Network Deconfounder,Causal Network Embedding,CFRNet, CEVAE, 和Causal Forest。
在Evaluation中,我们用估计出的因果效应和模拟出的ground truth相比较,并且探究模型在不同hidden confounding强度下是否具有robustness。
我们用了两个常用Metrics,如下图所示,越小则说明模型预测越好。

图8 Metrics
Results中,我们可以看到IGNITE表现优于the ablation models 和 the state-of-the-art methods,同时横向对比可以发现,当hidden confounding(K2)上升,IGNITE是error增加最少的模型。
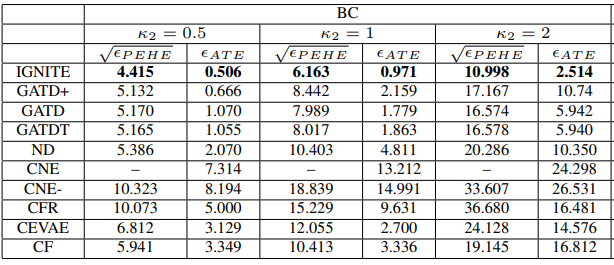
图9 Results
REF
Guo, Ruocheng, et al. "IGNITE: A Minimax Game Toward Learning Individual Treatment Effects from Networked Observational Data." IJCAI, 2020.
本篇论文地址:
https://www.ijcai.org/Proceedings/2020/0625.pdf
[1] Shalit, Uri, Fredrik D. Johansson, and David Sontag. "Estimating individual treatment effect: generalization bounds and algorithms." In International Conference on Machine Learning, pp. 3076-3085. PMLR, 2017.
[2] Veitch, Victor, Yixin Wang, and David Blei. "Using embeddings to correct for unobserved confounding in networks." In Advances in Neural Information Processing Systems, pp. 13792-13802. 2019.
[3] Kuroki, Manabu, and Judea Pearl. "Measurement bias and effect restoration in causal inference." Biometrika 101, no. 2 (2014): 423-437.
[4] Gulrajani, Ishaan, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C. Courville. "Improved training of wasserstein gans." In Advances in neural information processing systems, pp. 5767-5777. 2017.
[5] Johansson, Fredrik, Uri Shalit, and David Sontag. "Learning representations for counterfactual inference." ICML. 2016.
[6] Guo, Ruocheng, Jundong Li, and Huan Liu. "Learning individual causal effects from networked observational data." In Proceedings of the 13th International Conference on Web Search and Data Mining, pp. 232-240. 2020.
整理:李嘉琪
审稿:郭若城
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/ifBA8L)
(点击“阅读原文”下载本次报告ppt)
转载地址:http://zzwdb.baihongyu.com/